
Robots Txt Sitemaps in WordPress: SEO is the magic that ultimately decides the fate of your online presence. Proper use of SEO will mean more traffic is driving into your website and is generating popularity. Improper use of SEO could break your business and it may be difficult to continue to sustain a presence online.
The site needs to be thoroughly optimized so that website contents can be properly analyzed for information. This way, every time your company name or anything related to your company comes up, people will find your name in the search results.
The aim is to get your name to appear in the top three search results. Thus, to ensure maximum reach, the website must be comprehensively analyzed to be indexed correctly and appear first within search results. To do this, you will need to properly utilize robots.txt for WordPress.
Contents
Robots Txt Sitemaps in WordPress: What is Search Bot?
Search bots, also known as web crawlers, are meant to mimic spiders and how they crawl about. These internet bots methodically browse through the World Wide Web to conduct web indexing.
Indexing is the term used for collecting, storing, and parsing data. These are then quickly and accurately displayed to the audience whenever someone types in keywords looking for something. If it matches the content of certain websites, they will pop up on the search results list.
The indexing framework involves tapping into individual psychology, linguistics, information, etc. It incorporates advanced algorithms, mathematics, and computer science to navigate through intricate networks of websites on the World Wide Web.
This is also known as “web indexing”, which is the collection of data and information from the contents of a website or just the internet overall. Each website may opt to use a “back-of-the-book” index. Otherwise, dedicated search engines, generally make use of metadata and keywords to formulate a more favorable vocabulary list for searching on the internet.
Indexing is an important concept because without it, retrieving useful information would have been the same as going into a library and scheming through thousands of books to find information on what you are looking for. The information collected would perhaps not be enough since one source may not have all the detailed information.
Thanks to these search bots or web crawlers, information put forth by websites is indexed and all necessary details are recorded for immediate retrieval. Search engines fetch about 10,000 documents within just milliseconds which would take hours or perhaps even days to scan through manually in-page documents.
The internet has a mammoth number of pages available. As technology is evolving and more users are focusing on their online presence, the amount of information that bots have to process is increasing.
When search bots were only a budding idea, search engines were not able to show sufficient data results. They are now fully optimized and are constantly updating to show relevant results in an instant.
Search bots go around consuming resources on previously visited systems and often lurk in websites without admin approval. This gives rise to issues like scheduling and loading when large volumes of pages are infiltrated by bots all at once.
Moreover, unwanted entry into pages or folders gives the search bots leeway to gather information that is perhaps privy to the mass. Perhaps one or two pages of a website may be under maintenance or have a broken link.
Misinformation and faulty links might be shown to the audience instead of relevant information because the bots are processing whatever they are crawling into first.
This can be prevented by setting a list of instructions within the website directory for the search bots to follow. These instructions can and should include an approval list of where the search bots are allowed to navigate and where their access is blocked. This is neatly written in a file known as the robots.txt file.
What is a robots.txt File?
Countless websites are published on the internet daily and the way people find out about your business is when Google and every other search engine index find each element of the website.
Search engines conduct thorough research on all websites, thanks to its helping hands, search bots. These search bots crawl into website configurations and quickly scan everything to get information on what you are and what you do.
The search bots go everywhere, including the core of your WordPress website, the admin configuration file. You can prevent them from entering this file, or any files in general by adding the file name in the “Disallow” option.
robot.txt is a text-based file that contains instructions for search bots on how to visit pages on a certain website, standards that govern how search bots process the information, how to serve content to the audience, etc. It also contains protocols on where to go and where not to go. This protocol list is known as the “robots exclusion protocol”, or REP.
The REP includes instructions for directives such as meta robots, page-, subdirectory-, etc. The basic format is:
User-agent: [user-agent name]Disallow: [URL string not to be crawled] These two lines of code alone are what define a complete robots.txt file. Although one robot file may house multiple user agents, these two lines are the building bricks of a well-scripted robots.txt file.
This file, after creation, must be placed in the top-level directory of the website for it to work. Search bots will not be able to locate it if it’s placed anywhere other than the website’s root directory folder and thus they will go on a rampage collecting information here and there.
The file is also very case-sensitive. You must save the file as robots.txt, not Robots.txt, robots.TXT, ROBOTS_TXT, etc. Should you accidentally save the file as such, be sure to rename it or add the file again with the proper name.
robots.txt files are public information that anyone can access. Take any website and add “/robots.txt at the end of the URL and you should be able to see whether they have a robots.txt file or not. Thus, it’s suggestible to not utilize this to conceal private user information.
Why Do You Need a robots.txt File?
The primary reason for the robots.txt file to exist is to ensure that search bots do not crawl into pages they do not have any business in.
For instance, you would not want to search bots to access configuration files and perhaps alter elements of your website. This might happen if bots have the access to lurk around in your admin folder.
Moreover, bots have a “crawl quota” that permits them to crawl into a limited number of pages. You want to make sure that these are drifting into important pages and landing pages so that only the vital and necessary information is recorded and shown to the audience.
A well-scripted robots.txt file ensures that the bad bots are warded off which would otherwise hinder the performance of your WordPress website and make it slow. Thus, having the proper knowledge to edit robots.txt for WordPress will give your business a competitive edge.
How to Access robots.txt File in WordPress?
Now that you know why the robot.txt file is crucial, you might wonder where the robots.txt file is in WordPress. Finding the Robots Txt Sitemaps in WordPress location is a piece of cake. It’s automatically created and kept in the website’s root directory. To directly access them, all you have to do is:
- Open the website in your preferred browser
- Affix the link with a “/robot.txt” at the end. It should look something like this:
https://thisisawebsite.com/robot.txt
That’s it! There you have the robots.txt file!
How to Create Robots Txt Sitemaps in WordPress?
There are namely two ways in which you can create your robots.txt file to have more control over the search bots. You can either do it manually or go about it by taking help from WordPress plugins. Let’s take a look at both methods.
1. Plugin
Robots Txt Sitemaps in WordPress plugins make the job ten times easier. Simply download and install suitable and reliable Robots Txt Sitemaps in WordPress plugin. Next, navigate to SEO→Tools. You will come across a “File editor” option in your plugin dashboard. Open it and you will be redirected to where you can create a file using the “Create robots.txt file”.
In the empty text editor below, add or edit rules (all about creating rues coming right up!) to create a set of instructions.
2. Manual Input
No, no! You have absolutely nothing to worry about. You do not have to curate crazy codes to get this task done. All you have to do is:
- Open any text editor as long as it not a word document
- Type in the following rules:

- Save it as “robots.txt” in your device
- Upload it to your website using any good FTP client
Job well done!
How Do You Add Rules?
Before you learn how to add rules, learn what role they play in website optimization. Rules in this context are a pair of instructions: allow and disallow. As the names suggest, allow lets the bot access a file whereas disallow prohibits entry.
To allow entry, simply type:
User-agent: *
Allow: /wp-content/uploads/
The asterisk is what addresses the search bots. This invites them to read the instructions and function accordingly.
To prohibit entry, simply type:
Disallow: /wp-content/uploads/How to Test Your Robots Txt Sitemaps in WordPress File?
Of course, to warrant that the file is working its magic, you need to be able to test it. Thanks to Google Search Console, you can use their tools to quickly check it out. Making an account is easy, just log in with your Gmail ID.
- Log into your Google Search Console account
- Scroll down, look for the “Go to the old version” option, and click it
- In the dashboard of the previous version, look for “Crawl”→ “robots.txt Tester”
- In the empty text editor, Ctrl+V the rules you had previously added and then hit “Test”
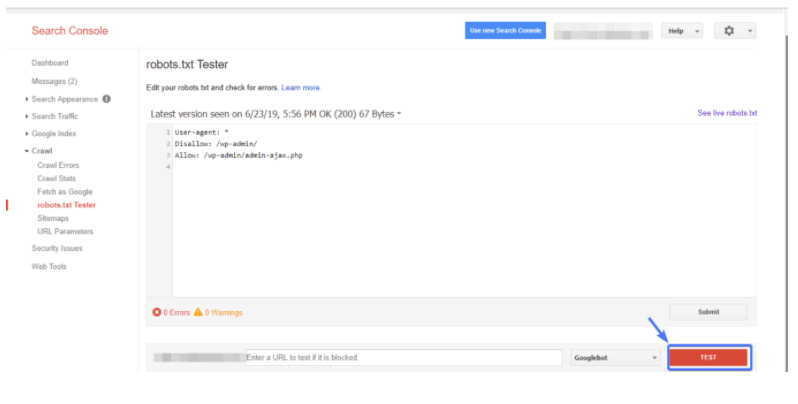
The Test button should read Accepted or Blocked. Make the needed changes and conduct as many tests as you would like until it works out for you. However, it must be kept in mind that the changes on the page are not saved on the site.
This means that you will have to either manually input the rules to your WordPress site or use a plugin to apply the changes.
See also:
All in One SEO vs Yoast: Which One’s Better? (5 Key Differences)
Stagging Meaning Update
Conclusion
Robots Txt Sitemaps in WordPress files are set in place to ensure web crawlers or search bots do not wander off to pages or files which the owners do not want them to access. Bots explore every aspect of your website to save information on you and list them in the search results for the general Joe to see.
However, they also have a limited number of pages or files they can crawl into. If they end up going into places where not much valuable information is listed, these would ultimately show up on the search results and spread information otherwise deemed undesirable.
Thus, you want the search bots to crawl in just the rights nooks and crannies of the website so that the people get to view exactly what they are looking for. Effective scriptwriting will allow the website to have a high ranking on the SEO front and score your website a top place in the search results.
Moreover, an enhanced robots.txt file will block the entry of harmful bots into your website and let the good ones receive the information you want to share. We hope this article has shed some light upon the confusion that had kept you from building a successful WordPress site.



